172 points by taubek about 18 hours ago | 64 comments | View on ycombinator
v1ne about 16 hours ago |
kjellsbells about 11 hours ago |
Since good documentation creates a consistent mental model in the reader, cultural affinity of the writer to both source (developer) and reader helps, and the old, much smaller, computer industry was able to pull that off. I sat two cubes from my doc writer and we shared the same cultural worldview with each other and our market. It's much easier to communicate in that milieu because so much can be left unsaid.
Its possible that we are entering a Golden Age of Text, where everyone realizes that they have to feed their AI with decent information in order to have any hope of it producing good answers (especially true for complex technical products and internal corporate processes). But I am not hopeful.
vintagedave about 17 hours ago |
I'd really like to see the Win2K-style docs on REST, for example.
Edit: it was right there, in bold, too. https://gist.github.com/theletterf/0b8ee1112fbd087f3141d0cad...
mybbor about 5 hours ago |
I jumped in and added working minimize/maximize/close buttons, a draggable window, and a Start menu, because of course. Brought back memories of young me learning Visual Basic to make AOL add-ons.
https://artdirectiondaily.com/issues/2026-06-05-docs-find-a-...
wxw about 9 hours ago |
Wonderful! Thanks for the introduction to this resource.
paultopia about 12 hours ago |
axus about 8 hours ago |
ethanlearns about 5 hours ago |
shye about 6 hours ago |
fga_qwrh about 9 hours ago |
LLMs work for half page answers of targeted questions. All longer prose is like swimming through molasses.
undefined about 13 hours ago |
badsectoracula about 12 hours ago |
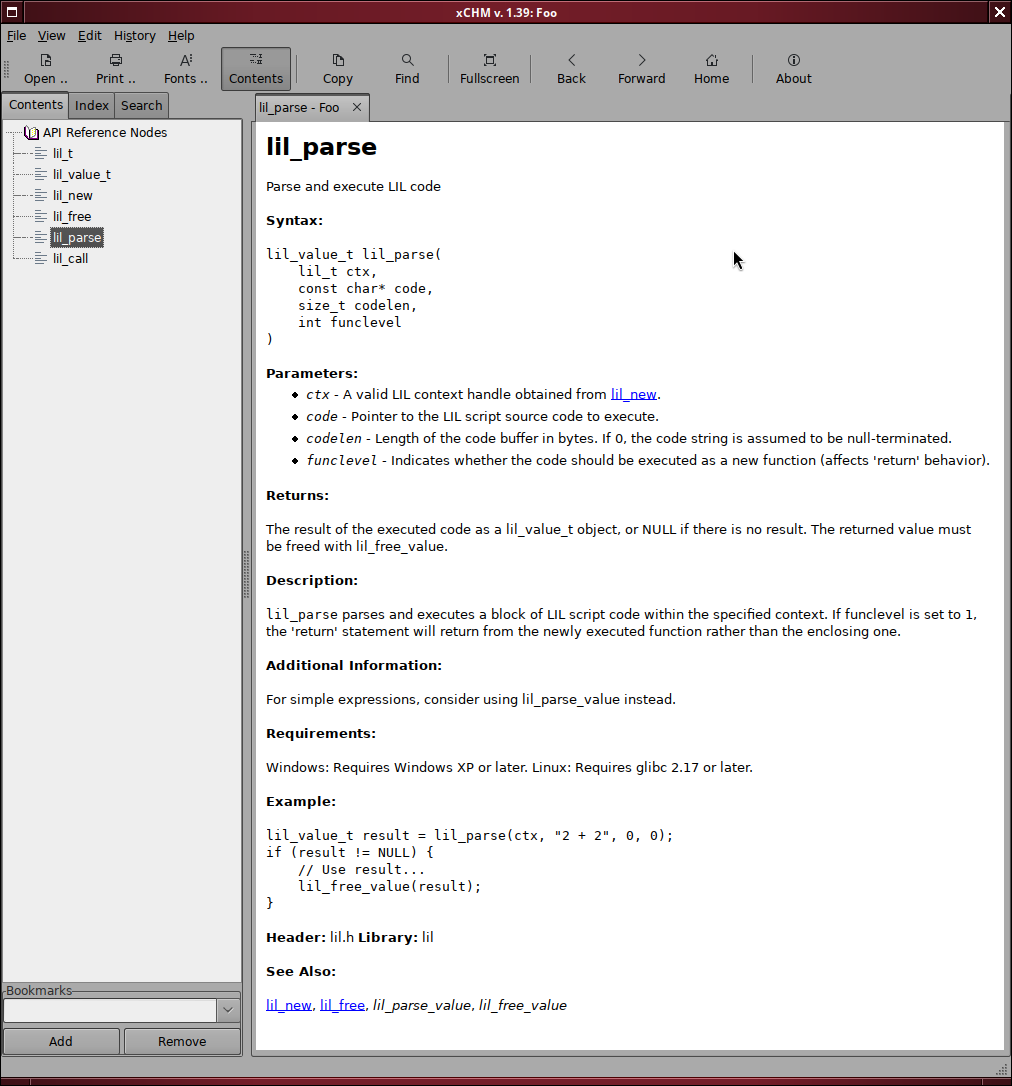
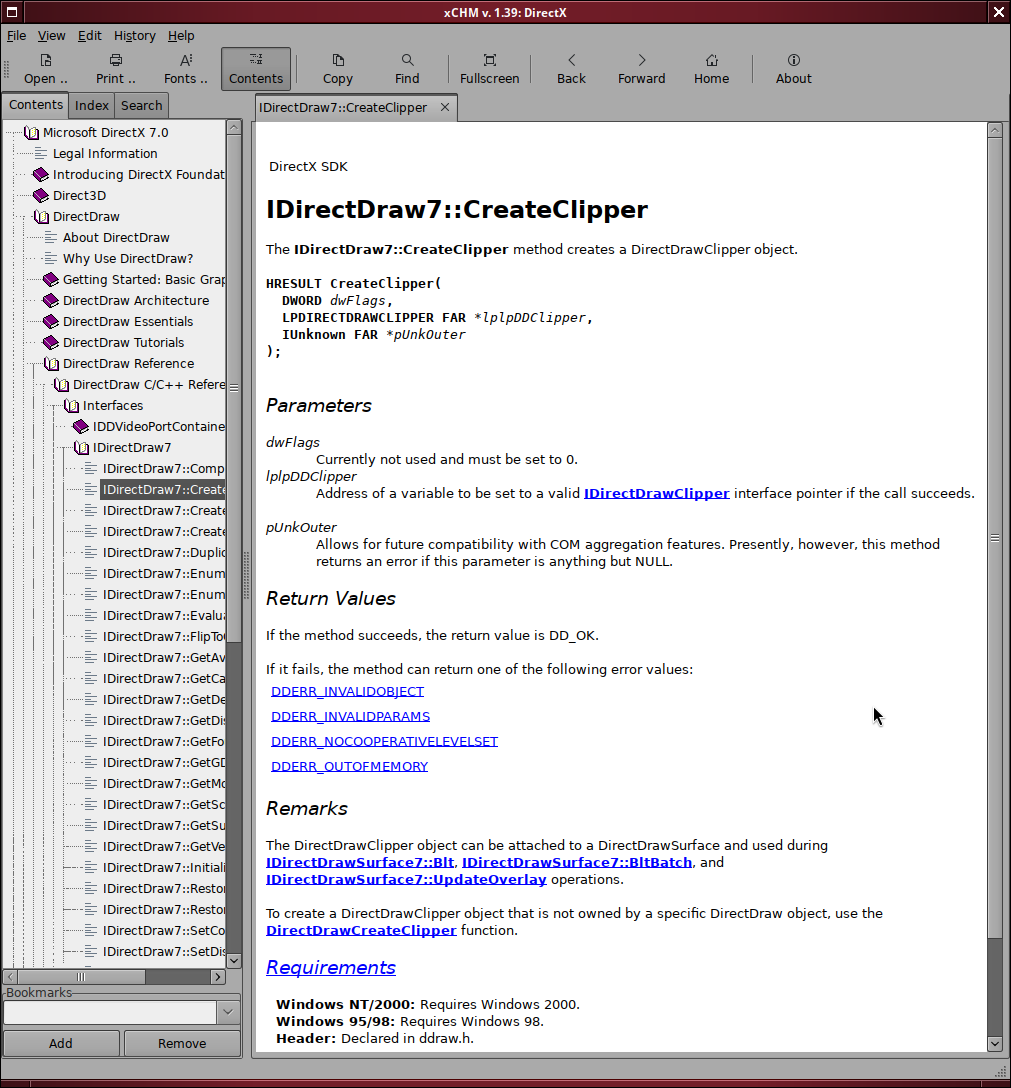
As an example i asked Devstral Small 2 to write some docs for my LIL scripting language in the following style (this is copied from the DirectDraw documentation, edited to be text friendly):
IDirectDraw7::CreateClipper
---------------------------
The IDirectDraw7::CreateClipper method creates a DirectDrawClipper object.
HRESULT CreateClipper(
DWORD dwFlags,
LPDIRECTDRAWCLIPPER FAR *lplpDDClipper,
IUnknown FAR *pUnkOuter
);
Parameters
* dwFlags - Currently not used and must be set to 0.
* lplpDDClipper - Address of a variable to be set to a valid
IDirectDrawClipper interface pointer if the call succeeds.
* pUnkOuter - Allows for future compatibility with COM aggregation features.
Presently, however, this method returns an error if this parameter is
anything but NULL.
Return Values
If the method succeeds, the return value is DD_OK.
If it fails, the method can return one of the following error values:
* DDERR_INVALIDOBJECT
* DDERR_INVALIDPARAMS
* DDERR_NOCOOPERATIVELEVELSET
* DDERR_OUTOFMEMORY
Remarks
The DirectDrawClipper object can be attached to a DirectDrawSurface and used
during IDirectDrawSurface7::Blt, IDirectDrawSurface7::BltBatch, and
IDirectDrawSurface7::UpdateOverlay operations.
To create a DirectDrawClipper object that is not owned by a specific
DirectDraw object, use the DirectDrawCreateClipper function.
Requirements
Windows NT/2000: Requires Windows 2000.
Windows 95/98: Requires Windows 98.
Header: Declared in ddraw.h.
See Also
IDirectDrawSurface7::GetClipper, IDirectDrawSurface7::SetClipper
[0] https://app.filen.io/#/d/9f4c1225-3527-4f16-a522-0678342120c...
[1] http://runtimeterror.com/pages/iv/images/45f8df428afe4fe6b6a...
[2] http://runtimeterror.com/pages/iv/images/ee58032790a049d7e74...
mock-possum about 17 hours ago |
Is that why though? You need a beast of a machine to run a functional local model in my experience.
I think the big part is there’s significant sticker shock to buying capable hardware.
That said,
> weekend. I chose to try fine-tuning on two models, Llama 3.1 8B Instruct and Qwen 2.5 7B Instruct. At their size (around 8B) they run comfortably on a MacBook Air
Perhaps I spoke too soon?
Anyway
> I chose the Microsoft collection as the source of training materials. The collection contains out-of-print docs published between 1977 and 2005: more than 37 million words, covering old systems and SDKs
this strikes me as a very specific brand of 1995’s prose, spanning about 30 years. It’s a cool article though, so maybe that’s a forgivably clickbaity title.
spacebacon about 16 hours ago |
https://github.com/space-bacon/SRT
The HF zool4nd3r demo may be useful
holoduke about 16 hours ago |
undefined about 9 hours ago |
sspoisk about 12 hours ago |
openclawclub about 10 hours ago |
DuduZhvania about 9 hours ago |
realfutureman about 13 hours ago |
m_m_carvalho about 8 hours ago |
openclawclub about 9 hours ago |
eddysir about 11 hours ago |
krupan about 11 hours ago |
{kind=link}
{kind=link}
Negative example: I was looking into the German manual of my Canon EOS R5 II, and it is just fluff. Hundreds of pages, full of white space, telling me about features without actually explaining what they mean. Awful automatic translations. Their manuals used to be good (looking at my EOS 6D). But these days: oh boy.